
Indhold

Kilde: Kran77 / Dreamstime.com
Tag væk:
Deep learning-modeller underviser computere til at tænke på egen hånd med nogle meget sjove og interessante resultater.
Dyb læring anvendes til flere og flere domæner og brancher. Fra førerløse biler, til at spille Go, til at generere billedmusik, der er nye dybe læringsmodeller, der kommer ud hver dag. Her går vi over flere populære dyb læringsmodeller. Forskere og udviklere tager disse modeller og ændrer dem på nye og kreative måder. Vi håber, at dette udstillingsvindue kan inspirere dig til at se, hvad der er muligt. (Vil computere være i stand til at efterligne den menneskelige hjerne for at lære om fremskridt inden for kunstig intelligens?)
Neural stil
Du kan ikke forbedre dine programmeringsevner, når ingen er interesseret i softwarekvalitet.
Neural Storyteller

Neural Storyteller er en model, der, når de får et billede, kan generere en romantisk historie om billedet. Det er et sjovt legetøj, og alligevel kan du forestille dig fremtiden og se i hvilken retning alle disse kunstige intelligensmodeller bevæger sig.

Ovenstående funktion er den "stilskiftende" operation, der gør det muligt for modellen at overføre standard billedtekster til historienes stil fra romaner. Stilskift blev inspireret af "En neural algoritme af kunstnerisk stil."
Data
Der er to hovedkilder til data, der bruges i denne model. MSCOCO er et datasæt fra Microsoft, der indeholder omkring 300.000 billeder, hvor hvert billede indeholder fem billedtekster. MSCOCO er de eneste overvågede data, der bruges, hvilket betyder, at det er de eneste data, hvor mennesker var nødt til at gå ind og udtrykkeligt udskrive billedtekster for hvert billede.
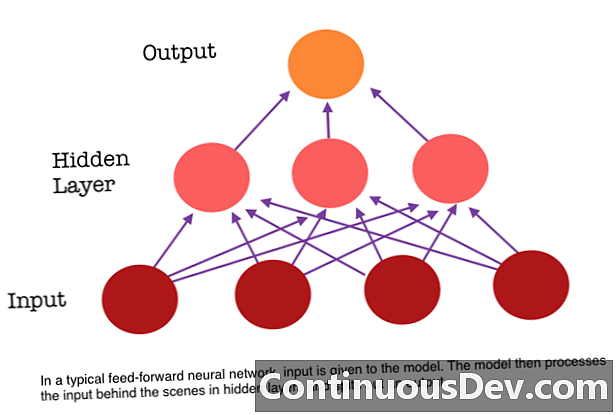
En af de største begrænsninger i et feed-forward neuralt netværk er, at det ikke har nogen hukommelse. Hver forudsigelse er uafhængig af tidligere beregninger, som om det var den første og eneste forudsigelse, som netværket nogensinde har foretaget. Men for mange opgaver, såsom oversættelse af en sætning eller et afsnit, skal inputene bestå af sekventielle og konjunkturrelaterede data. For eksempel ville det være vanskeligt at give mening om et enkelt ord i en sætning uden de ulemper, der er givet af de omgivende ord.
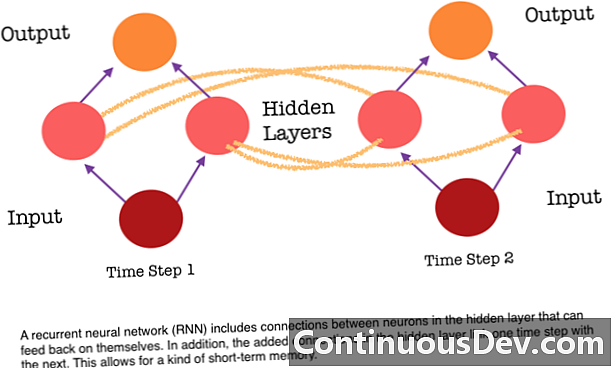
RNN'er er forskellige, fordi de tilføjer et andet sæt forbindelser mellem neuronerne. Disse links tillader aktiveringerne fra neuronerne i et skjult lag at fodre tilbage i sig selv på det næste trin i sekvensen. Med andre ord modtager et skjult lag på hvert trin både aktivering fra laget under det og også fra det forrige trin i sekvensen. Denne struktur giver i det væsentlige tilbagevendende neurale netværkshukommelse. Så til opgaven med objektdetektion kan en RNN trække på sine tidligere klassifikationer af hunde for at hjælpe med at bestemme, om det aktuelle billede er en hund.
Char-RNN TED
Denne fleksible struktur i det skjulte lag gør det muligt for RNN at være meget god til sprogmodeller på karakterniveau. Char RNN, oprindeligt oprettet af Andrej Karpathy, er en model, der tager en fil som input og træner en RNN til at lære at forudsige det næste tegn i en rækkefølge. RNN kan generere karakter efter karakter, der vil ligne de originale træningsdata. En demo er blevet trænet ved hjælp af transkriptioner af forskellige TED-samtaler. Indfør modellen et eller flere nøgleord, og den genererer en passage om nøgleordene i stemmen / stilen i en TED Talk.
Konklusion
Disse modeller viser nye gennembrud i maskineintelligens, der er blevet muligt på grund af dyb læring. Dyb indlæring viser, at vi kan løse problemer, som vi aldrig kunne løse før, og vi har endnu ikke nået dette plateau. Forvent at se mange flere spændende ting som førerløse biler i de næste par år som et resultat af dyb læringsinnovation.